Daniel2 Codec Development Update
December 2019
Cinegy has a longstanding relationship with NVIDIA and now we go beyond supporting Daniel2 GPU acceleration on PC-based NVIDIA GPU cards. We now support the increasingly popular range of NVIDIA System-on-Chip (SoC) products, which combine ARM processors with NVIDIA GPUs and most other functionality to make a whole computer fit in one chip only needing to add RAM and flash or disk storage.
The world of NVIDIA SoCs starts with the inexpensive entry-level NVIDIA Jetson Nano developer board ($99) with four ARM cores, 4GB shared RAM, 128 Maxwell CUDA cores, which has just enough power for UHD. This scales up to all the way to the Jetson AGX Xavier developer board ($709) with eight ARM cores, 16GB shared RAM and 512 Volta CUDA cores, which is enough to handle 8K. The NVIDIA SoCs are ideal for embedded solutions for recording and playing back Daniel2 UHD or 8k video.
Generic ARM support is being finished which opens the world of ARM-based smartphones, tablets, action cams, drones, and tons of other ARM CPU powered devices. ARM CPU support is for 64bit capable CPUs only and supports NEON acceleration which is the ARM equivalent of Intel’s SSE. Currently a QUALCOMM Snapdragon 855 ARM CPU, as used in smartphones such as the Samsung Galaxy S10, can encode and decode around 95fps of UHD 4:2:2 10bit Daniel2 video, but the performance will be further optimized before release.
- D2 CPU decoder has been further optimized – 25% speed gain
- D2 CPU encoder has been further optimized – 36% speed gain
- Fast inline scaling was added into the CPU decoder (for factors x2 to x8). This allows 2-core CPU based playback of Daniel2 8K video files scaled down to HD using Adobe Premiere – already implemented in shipping Adobe Premiere plugin (both for Windows and Mac).
- GPU inline scaler decoder implementation will come in 2020 and more scaling factors will be added.
- Added DirectX interop – to avoid GPU to CPU to GPU round-tripping
- Added direct Daniel2 GPU decoder output into DirectX/OpenGL textures
- Number of natively supported color formats has been increased (RGB24/30/36/48 and V210 formats are added to GPU mode) • Added fast inline RGB-YUV color conversion
- AVX512 optimization (experimental)
- Graceful quality degradation 'til zero - increases the quality on low bitrates, from 0.5 to 3-4 dB in extreme cases
- AES256 encryption / decryption (experimental) • Variable frame rate MP4 format support (experimental)
- Optional built-in PSNR calculation inside the encoder – currently comes with a 30% performance penalty when activated (experimental)
- New Cinegy Cinecoder / Daniel2 ARM 64bit version with NEON acceleration (experimental) – e.g. ARM SoCs like the Raspberry Pi4, ARM based smart phones and other devices. Currently up to 95 fps UHD 422 10bit on QUALCOMM Snapdragon 855 for both encode and decode.
- New Cinegy Cinecoder / Daniel ARM 64bit version with CUDA acceleration (experimental) – e.g. for Jetson Nano, TX1, TX2, Xavier and similar Nvidia SoCs or Nintendo Switch, Stealth TV, etc.
- Compression efficiency was improved up to 15% for both CPU and GPU
- Further decreased CPU load on GPU decoding
- Support of ultra large frame sizes of 64K x 64K and beyond further optimized. Playback with Cinegy Player3 of up to 32k tested.
- New versions of the Adobe CC plugins (Windows and Mac) were published beginning of November with additional audio export options, bug fixes and the latest Daniel2 updates. In parallel a new version of Cinegy Player3 was made public.
(experimental) = features are working only in non-public, internal development and testing branches
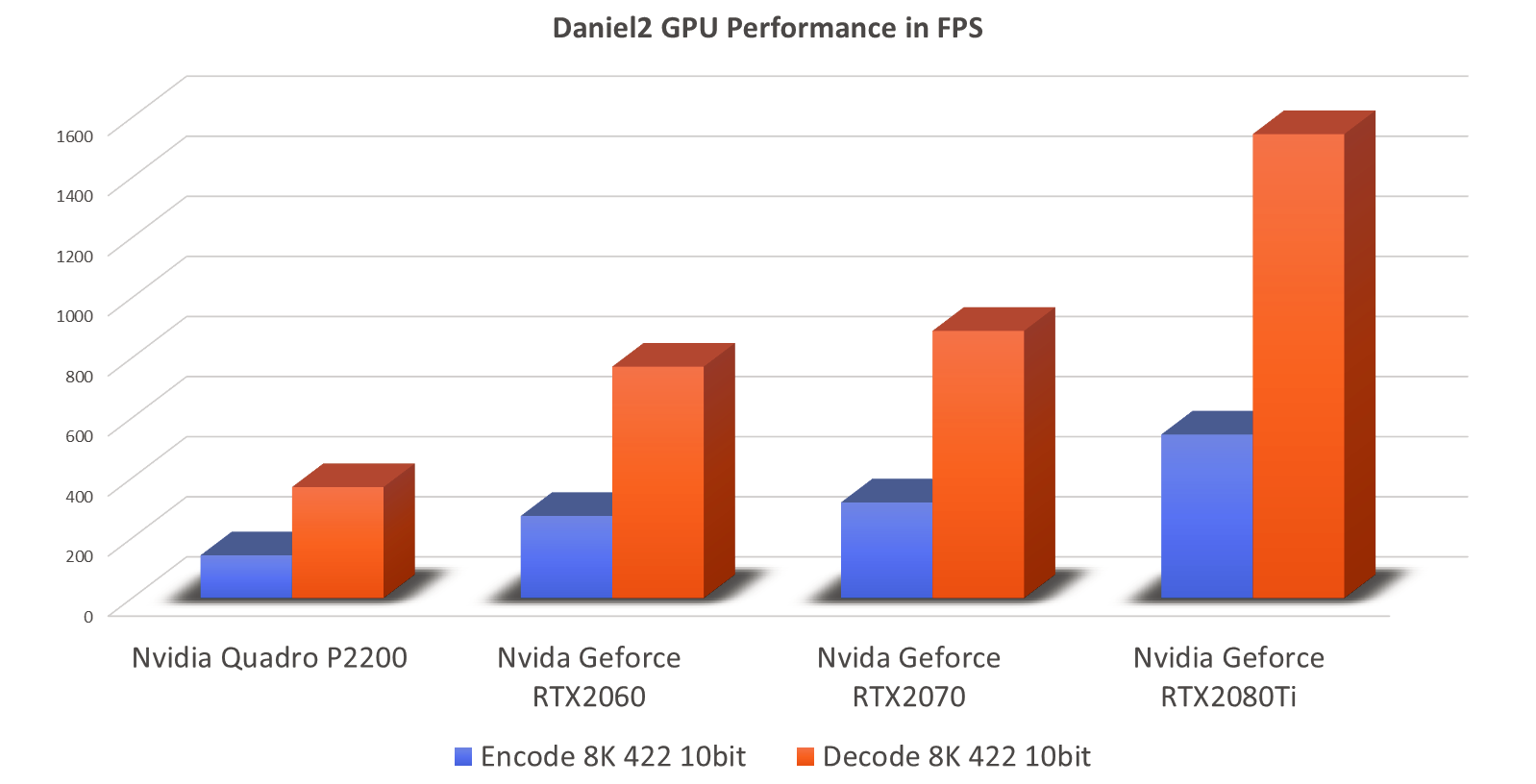
Daniel2 GPU Performance Benchmarks
The results depicted in the bar chart below were generated using a simple benchmark based on uncompressed YUY2 8K image as source loaded into GPU RAM with the encoded data written to nil, respectively a compressed Daniel2 8K image is being read from GPU RAM and decompressed with the decoded image output written to nil. The Nvidia Geforce RTX2080Ti, fastest card in this test range, can encode 545 FPS of 8K 4:2:2 10bit and decode 1545 FPS of 8K 4:2:2 10bit. This means the encode performance is higher than what can be possibly pushed to the GPU via the current PCIe 3.0 x16 bus connection or even a future PCIe 4.0 or PCIe 5.0 connection. This is not necessarily a problem as the GPU can be used for many other processing tasks at the same time – e.g. de-bayering, de-noising, color correction, color space conversion, scaling and much more.
The GPU decode speed is generally three times higher than the encode speed. In case of the RTX2080Ti the result for decoding 8K 4:2:2 10bit is 1545 FPS. For full HD this means almost 25000 FPS. To put this into perspective - a 90 minutes 24fps full HD or 2K movie can be decoded in less than six seconds with this GPU. There are faster Nvidia GPUs and one can use multiple GPUs in one server system (currently up to 8x). An entire 90min 2K 4:2:2 10bit movie could be decoded in half a second, a 4K movie in two seconds and a 90min 8K movie in under eight seconds. In theory. Practically we so far have only managed 28 GB/s disk speed to feed the decoder which was using eight striped NVMe SSDs. With PCIe 4.0 based SSDs we should be able to double this.
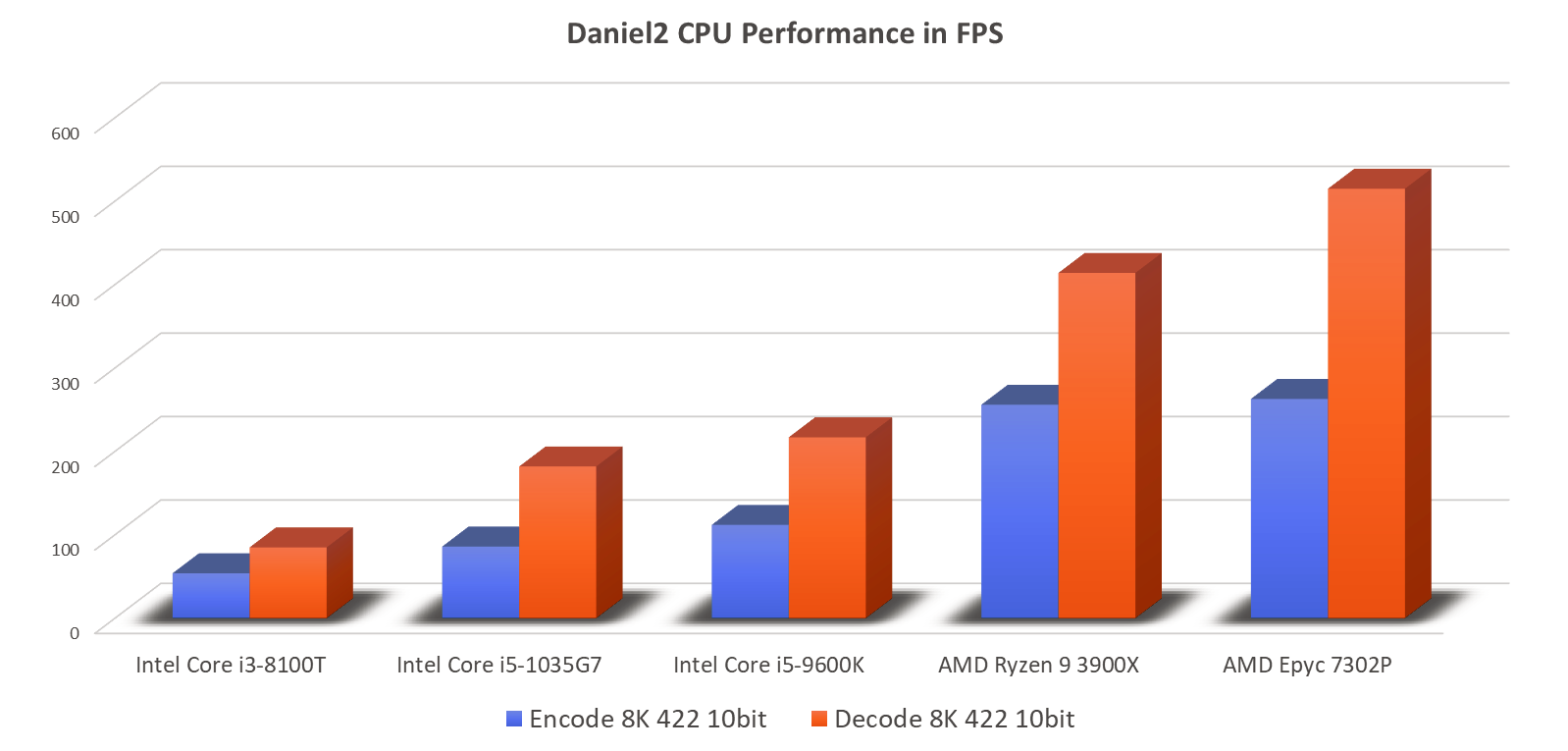
Daniel2 CPU Performance Benchmarks
The benchmark setup is the same as for the GPU, but of course instead of GPU RAM the system RAM is being used. The fastest CPU in this (limited) range is a single 16-core AMD Epyc 7302P processor, which currently would represent the lower mid-range server class. Again, looking at 8K 4:2:2 10 bit this processor can encode 263 FPS of and decode 515 FPS. Even when running the overhead of a more complex application such as Cinegy Capture PRO, this is enough performance for capturing two channels of 8K60 and still having a lot of spare performance left for other tasks. Top range processors available today are up to 3-4 times faster (e.g. a 64-core AMD Epyc 7702) and two of these processors can be installed in a system. This would then result in a 6-7x higher aggregate system performance than that measured for a single Epyc 7302P. This also means that capturing more than 10 channels of 8K60 with a single server is possible today with the bigger limitation being where to put all the SDI PCIe cards.
The Ryzen 9 3900X 12-core CPU is almost as fast as the Epyc 7302P, but at less than half the price. The main problem with the AMD Ryzen is the limited amount of PCIe slots supported compared to AMD Epyc, AMD Threadripper or Intel Xeon based solutions.
On the low-end side of the results we find an Intel Core i3-8100T (35W TDP) which is too slow for 8K60 encoding (54 FPS), but a newer Core i5-1037G5 laptop CPU, with a TDP of only 15W, is fast enough to encode 8K60 with 86 FPS or being able to do 182 FPS decode. This 10th generation Intel CPU is more efficient than FPGA based solutions and the same processor can handle other tasks in parallel such as storage, network and display.